
The AI doppelgänger experiment – Part 1: The training
👯 On training my own AI to steal illustrators’ styles

‘And only one for birthday presents, you know. There’s glory for you!’
‘I don’t know what you mean by “glory”,’ Alice said.
‘Humpty Dumpty smiled contemptuously. ‘Of course, you don’t–till I tell you. I meant “there’s a nice knock-down argument for you!”’
‘But “glory” doesn’t mean “a nice knock-down argument”, Alice objected.
‘When I use a word,’ Humpty Dumpty said in rather a scornful tone, ‘it means just what I choose it to mean–neither more nor less.’
‘The question is,’ said Alice, ‘whether you can make words mean different things–that’s all.’
‘The question is,’ said Humpty Dumpty, ‘which is to be master–that’s all’
This passage of Alice Through the Looking Glass is often cited in philosophy of language classes to introduce the idea of language as a social activity that rely on shared meaning. If the same word means different things every time we use it, or different things for different speakers, how could we communicate at all? As I’m researching the social life of images through the fields of illustration, design, law, machine learning, and so on, I’m often reminded of Humpty Dumpty. While illustrators, designers, lawyers, and computer scientists might all use the same words —images, style, art— they rarely share the same meaning. But unlike Alice and Humpty Dumpty, instead of having a conversation about what they mean when they use a word, the people talking about AI and art continue to yap at each other endlessly in mutual misunderstanding. The goal of course, is not mutual understanding, but power, or as Humpty Dumpty puts it, to decide “which is to be master”. Without ever addressing the linguistic nature of the debate, proponents and opponents of generative AI are indeed fighting for the power to define what “image”, “style”, “art” mean.
Communication relies on shared language, and when this communication is about what we see, it also relies on shared ways of seeing. Yet, different people learn to see the same things differently and these ways of seeing, as John Berger pointed out, are socially constructed. What does an artist see when they look at their style? How does it differ from the ways machine learning models see styles? And which way of seeing has more power?

Human and machine ways of seeing style
To start answering these questions, I interviewed computer scientists working on generative AI about “style transfer”, the process of extracting the stylistic features of an image to apply them to another. Both as an illustrator and an anthropologist, I was fascinated by the idea. When I ask illustrators to describe their style, they usually go on long narrative tangents about what they love, how they grew up, who they know, etc. Style is a deeply lived category, a repository of experiences and influences that resists simple definitions. I wondered how computer scientists could create systems that translated this in mathematical vectors that could be extracted from a mere image. How they defined “style”, how they trained a model to pick up on it, and how much of our own perception and the ways we learn to look at images, are all very exciting questions to me.
The main takeaway of these (ongoing) interviews so far has been that computer scientists are interested in style not in itself, but for the challenges that it confronts machine learning models with. Training a model to transfer the style of an image to another involves for that model to take a whole entity, the image, and divides it in layers that are not pre-given in the data itself. In this case, the layers are the denotational content of the image, what it represents, and its stylistic, or formal treatment. This is an impressive feat for a machine learning model to be able to achieve this. But the very notion that artworks can be separated in these two aspects, denotational and stylistic, is itself an old idea that can be traced to early twentieth century art historian Heinrich Wölfflin (1864-1945) work on formalism. For him, it was important to study artwork from a formal point of view, without considering their subject.
We rarely hear about the historical ideas that shape the thinking of technologists, that’s the whole point. Technology is meant to be innovative, disruptive, and the lobbying of AI company is in part of cultural lobbying to erase the historicity of their ideas in order to constantly situate their work in the future. So how does an early twentieth century idea about art shows up in AI work today?
As often, it shows up in the unquestioned parts of the process of training a model. Computer scientists have often told me how none of them really has a working definition of style they consciously encode in a model:
“It's not very easy to define exactly what style is. But then you have these papers that say ‘Okay, what we're doing is, without defining exactly what style means we're showing you a method that can take an image, which we'll say we'll copy the style from, and we can transplant this style onto another image’. And you get a result that you look at and intuitively you say, ‘Okay, it's another object in the same style’ even if you don't know how to define its parts.”
The success or failure of style transfer relies not only on an algorithm, but on the “intuitive” perception of a beholder. This means both machine and human ways of seeing are co-constitutive of the resulting model. Another computer scientist shared that when training their own model, they worked with a designer whose job was to evaluate the quality of the output of a style transfer. The success of the model here became entangled with the taste of the perceiver parsing through outputs, selecting the best, i.e. the output that fit best our culturally specific idea of style. Far from an emergent inexplicable feature of the model, separating content from style is most often the result of tinkering, subjective perception, selection, and more tinkering, all steeped in very human ideas about what images are made of. So, how can I study this very subjective perception?

On looking looking
Ways of seeing are a slippery object of study. Unlike the linguistic anthropologists who trained me to study language, I (realistically) cannot record and transcribe “looks” like I would with words. Instead, I’m chasing ways of seeing in various corners of multiple meaning-making practices, from the moodboard designers create to the feedback illustrators get from art directors, from the captioning of a dataset to the prompting of a model. As AI companies are not exactly as open as they promised to be, I’ve decided that instead of spending months negotiating access to secret spaces protected by NDAs, I might as well take the experimental road, and train a model myself.
To do this, I contacted an amazing PhD researcher in Human-Computer Interaction at the University of Columbia, Sitong Wang, to work together on this. Working with another researcher was not only a way for me to ensure I would have someone who can explain to me what’s going on, but also to work with someone with the same ethical concerns I have about working with machine learning and people. Together we created an experimental protocol that would allow illustrators to participate and train the model on their own work in a safe environment, and get the opportunity to generate images themselves, thus placing human and machine in interaction to answer the question: What is generated in the encounter between human and machine ways of seeing?
Here's how we went about setting up a Human-Computer Interaction (HCI) experiment, within the larger context of my ongoing ethnographic fieldwork with New York creatives, and some insights we gathered along the way.

How to chop an image with words
Firstly, Sitong found the simplest and safest way to fine-tune a model and ended up choosing to do so with a LoRa, or Low Rank Adaptation. One of the main limitations of regular models like Stable Diffusion or MidJourney is that one cannot maintain a subject through several generations. This means that the description of a character would lead to wildly different results from one output to the next. LoRa was initially created to teach a model to learn a concept, for example a given character, that could then be generated consistently through many images. Interestingly, the model has been since then widely used to teach models not to recognize the subject of an image, but its style, leading to the now infamous case of Hollie Mengert’s work getting ripped off.
Once the LoRa was installed and set up, we had to feed it our first dataset, a.k.a 30 of my own precious illustrations. But the images alone are not enough for the model to learn to see their style, I had to caption each illustration describing what it was showing, leaving unwritten how it looked. Captioning a dataset is a process fraught with arbitrary choices that while seemingly “intuitive”, was for me a very complex task to wrap my mind around. The goal of captioning is to teach the model that everything described in the caption will be the replaceable features of a dataset, what will be flexibly generated by prompting it later. This means that everything else, that is not described in captions, must be retained as something to apply to all output. As one Youtuber explains, captioning is therefore a powerful semiotic action:
“[…] because the more details you input the more precise the model is going to be. […]If you have only 20 images it is going to be pretty fast but if you have more images that's really gonna take a while. I really wish that we had some sort of software that could do it automatically but as of right now the best tool is human eyes.”
So much for an automation.
My favourite way to think about this problem of captioning is Gregory Bateson’s boot. Bateson was a famous anthropologist, known for his interdisciplinary work spanning biology, psychiatry and social sciences and his founding role in the field of cybernetics in the 1950s. He was interested in the patterns that govern our lives, and the relation between parts and whole. To teach this to his student, he would use this figure:
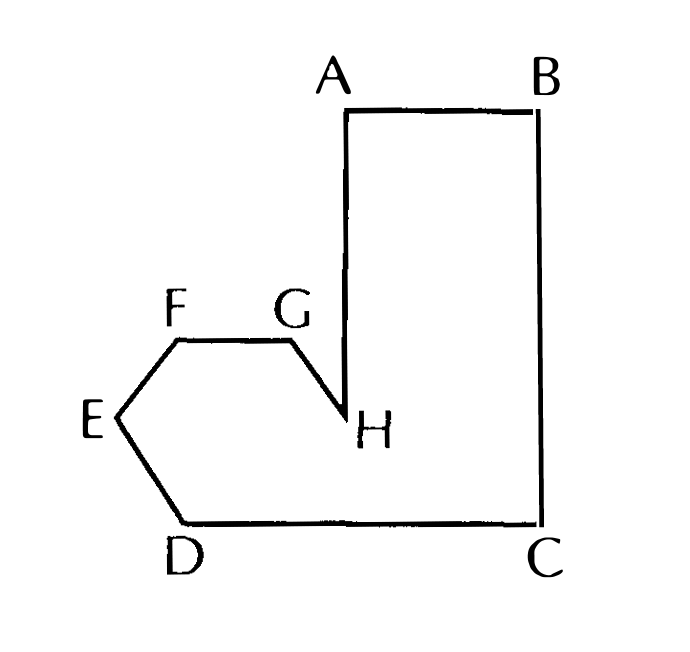
He would ask the students to describe it, and then compare the results. I’m not going to describe all the answers as you can watch a short video focusing on the exercise here:
As different students describe the figure using different strategies (the way it looks, the way it can be broken into parts, etc.), Bateson tells us that “we can get a certain amount of agreement about what's really there but we cannot get an agreement about ways of describing it and we use in the description a whole mess of concepts of intervening variables and mentionables to get our stuff across.” In other words, when using words and concepts to “describe” something we see, we inevitably impose on this object the limitations that come with description.
A dataset is like a massive Bateson boot, full of complex images (expressed as numerical vectors) tied to simple words (expressed as numerical vectors). In this pairing between the sprawling complexity of our visual world and its neat description by words, much is lost. As I’m sitting at my laptop trying to come up for a caption for each of my illustration, I panic. My brain can’t seem to be able to precisely locate where meaning happens in my work, nor can it separate in neat layers the images I’ve made between style and content. The message is the medium. I try to think about how I work, my relationship to a brief, the process of sketching and the role of language in it, maybe there’s in the process of making an image the key to understand why it’s so hard to describe it.
I realize that, despite working with texts (briefs, articles, etc.), there’s always a moment when I let go of language. I usually read the text once, and then work with whatever afterimage I have left of its meaning. Part of that meaning gets transferred in the things I draw, maybe a corpse and a bookshelf because the text is about corpses in literature.

But also, the way I choose to depict this corpse is a cut out, which I only realize as I’m sketching, because the art director suggested a two-image layout which allows for a sense of time, a sequence. Suddenly the corpse is not represented in the image but cut out from it, and only becomes the subject of the second image. All of this happens silently, keeping language at bay, to allow visual meaning-making to happen on its own. We’ll return to language later, as I get feedback from the art director and we fine tune the final image, but that process of making images from text is in large part non-linguistic, and therefore hardly contained by the linearity of neither captioning nor prompting.
In taking the relationship between words and images as a simple 1:1 ratio, machine learning models sacrifice much of what illustration is really about, i.e. the space between text and image. This is not to say they do a bad job, they just do a very different one than illustrators do. They see images in a very different ways illustrators see them. The division between words and images is not the only one that is being flattened in most discussions of generative AI, another crucial one is that between images and people.

Being a person and a commodity in the uncanny valley
Once she trained the model on my work, Sitong and I meet up on Zoom. She shares her screen and shows me a series of 10 images of a woman wearing a cap. Put together on a spectrum, the images shows how the original image (a photorealistic AI image of the woman) gradually turns into a Julien Posture version of itself.

As I’m contemplating this Cronenberg-like transformation of the image, I can’t help to be struck by the triviality of my own work. There’s something confronting in facing a computational doppelgänger, something akin to the uncanny valley. I’m surprised at how much this affects me, even though my whole schtick is to be reflexive and critical about style, what surprises me the most is that even though the output if “objectively” a failure1, I see myself in it. But maybe what I see in the generation, what I find actually disturbing, is the part of my work that has already been objectified and commodified, the parts of my style I spent years making digestible for clients, consistent for social media, and reproducible for easy production.

As I extend the invitations to various illustrators, some categorically refuse, seeing one’s life work so easily reproduced would be too challenging they tell me. I understand. I went in this experiment confident about the distance I have with my own style, only to be shaken by the uncanniness of existing in a computational form. Is this the way people see my work? A mere surface, a bundle of shapes and colours slapped onto any idea.
On April 30th, British artist FKA Twigs testified in front of US senate about her experience and thoughts about AI. Her testimony weaves in the same breath issues of personhood and economic livelihood, identity and intellectual property, essence and superficiality:
“I am here because my music, my dancing, my acting, the way that my body moves in front of a camera and the way that my voice resonates through a microphone is not by chance; they are essential reflections of who I am. My art is the canvas on which I paint my identity and the sustaining foundation of my livelihood. It is the essence of my being.”
As many artists navigating the AI waters, Twigs must negotiate a delicate balance. On the one hand she mobilizes deeply emotional registers showing the inherent entanglement of her identity with her work, the “essence of [her] being”, on the other hand, she must clarify she’s not a luddite, and that her argument is mostly a rational, economic one. In fact, later she reveals having trained her own model in her likeness “to extend my reach and handle my online social media interactions, whilst I continue to focus on my art from the comfort and solace of my studio.”
As I’ve written before, illustration is a practice that turns artists into sort of hybrids between people and images. Illustrators style is both a very personal thing and a valuable commodity, and as illustrators’ images circulate online, fragments of themselves do too. Returning to the court, this ambiguity is best captured by Adobe’s proposition of the FAIR act (Federal Anti-Impersonation Right) which is a blend of copyright and right of publicity, conceptualizing style mimicry as a form of impersonation (see what I mean by hybrid between people and image?).
In lawsuits between AI companies and artists, these differences become flattened in the supposedly neutral gaze of the law. Machine learning models are constantly personified, the processes in their black box likened to that of artistic inspiration, meanwhile, artistic processes are mechanized, made simple and linear. The AI doppelgänger experiment is a way to zoom in on these tensions and ask, with artists, what is the difference between a person-created image, and a machine-generated one? And can we qualify this difference in ways that are productive for technological, legal, and social conversations about AI and creativity?

A notification chimes on my phone, it’s D., an illustrator who will be testing the model soon, “when are you finally gonna copy my art — Can’t wait to see it”. The model has now been trained enough times, it’s ready to be used with prompts. D. will be the first one to try it. I’m looking forward to it. I’m also a bit worried. Will this be a triggering experience for the illustrators I work with? Or will this be vindicating? What will be generated in the encounter between human and machine ways of seeing?
[Thumbnail image: Le diverse et artificiose machine, Agostino Ramelli, 1588]
Note that these are training results, the final fine-tuning was much more successful at emulating my work. But this is a story for part 2!